

NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
Journal Article Tag Suite Conference (JATS-Con) Proceedings 2010 [Internet]. Bethesda (MD): National Center for Biotechnology Information (US); 2010-.

Bookshelf is a digital collection of texts in life sciences and healthcare, at the National Center for Biotechnology Information (NCBI), National Library of Medicine (NLM). It currently includes roughly 700 titles, mostly textbooks, government or technical reports, and electronic publications. Content is submitted to Bookshelf by publishers and authors wishing to participate in the Bookshelf project. Supported by the PubMed Central (PMC; NCBI’s digital archive of full text articles) infrastructure for publishing and archiving and NCBI’s powerful Entrez system for search and retrieval, users can freely gain access to the content, which is closely integrated with other databases at NCBI such as PubMed and Entrez Gene, allowing discoverability of important clinical and scientific information.
Bookshelf maintains its content in XML conforming to the Book DTD of the NLM Journal Article Tag Suite (1). Several workflows exist to handle the conversion from various input formats to the Bookshelf XML standard. This paper discusses how the NLM Book DTD is used in Bookshelf within the context of PMC, the various workflows in Bookshelf, and mechanisms to integrate content at NCBI.
Introduction
Initially, for encoding its content, the Bookshelf used a DTD which was based on ISO 12083 and then continuously modified, in order to meet the changing needs of the evolving project. After publication of the NLM Journal Archiving and Interchange Tag Suite, the Bookshelf began migration of all book content to the NLM Book DTD. With a data format very closely related to the journal content published by PMC, it became feasible to integrate Bookshelf into the larger and more robust PMC infrastructure. Where the content was previously processed, stored, and delivered separately, leveraging off the mature system of PMC promised higher quality at lower cost. This paper attempts to illustrate how this promise held true. It focuses primarily on the basic condition that made close integration of books and journals possible: the use of a shared tag set that allows separate description of both types of publications where necessary, but employs the same content models where possible.
The NLM Book DTD in Context of JATS
As a member of JATS, the Book Tag Set was designed along the same broad conceptual lines as the article tag sets. Most notably, the model intends to describe the content, not the form of books and chapters. The DTD seeks to regularize and normalize the captured text. It does not claim to preserve all unique features and idiosyncrasies intrinsic to a particular format such as to a print publication. This is an important difference to other prominent book tag sets, especially TEI (Text Encoding Initiative; [2]). The NLM Book DTD, for example, does not include elements to describe typical print objects such as a title or copyright page per se, but expects the key information contained in these objects to be extracted and summarized in a <book-meta> model. Textual features exclusive to the paper format, for example page breaks, line breaks, running heads, or print ornamentation and frontispieces cannot be captured in form of explicit elements. Similarly, text objects that make sense in printed form, but are obsolete or can be auto-generated in an electronic environment are omitted. Thus the DTD does not feature elements, such as <toc> or <index>.
In line with the journal tag set, the book DTD also calls for a higher abstraction level in describing text. Where the article modules do not include elements, such as <book-review> or <letter>, the book DTD does not offer element-level differentiation for book sections like <preface>, <foreword>, or <introduction>. It describes the main text object in broader categories (such as <book-part> or <sec>) and relegates more granular differentiation to the attribute level.
A seemingly trivial, but fairly important difference between the book and the article modules is the nature of the top-level element. A book represents text at a higher composition level than an article. While it is possible to include (republish) an article in a book, the opposite is not true. Thus there are two basic units, not one, in the book modules: <book> and <book-part>, with the latter corresponding in nature to an article, as the following schema illustrates:
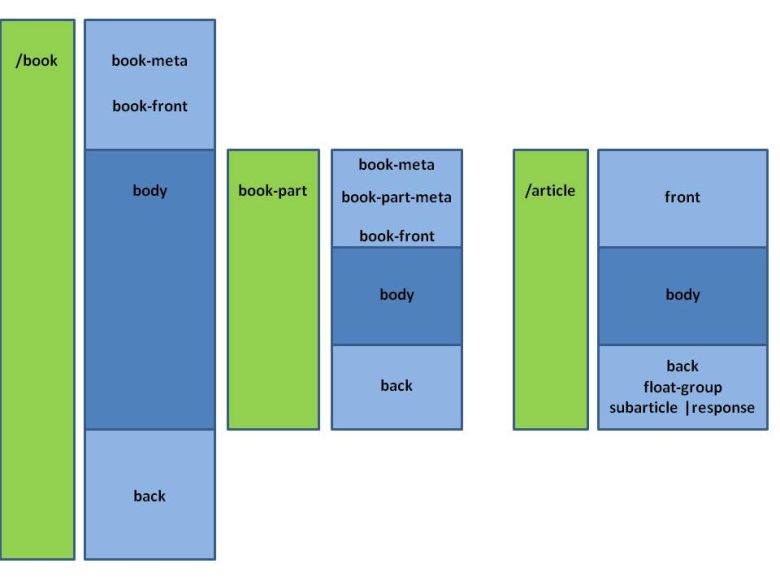
Apart from the overall structure and of course the basic bibliographic descriptors, the difference between articles and books are minor. <body> of <article> is almost identical to <body> of <book-part>. The only difference worth noting stem from particular historic needs at Bookshelf:
Firstly, the book DTD provides a mechanism to encode client-side image maps into the XML via the <map-group> element and its children, borrowed from (X)HTML models:
<map-group id="my-map-id">
<graphic xlink:href="img-uri"/>
<map map-name="my-map">
<area map-shape="rect" map-coords="1,1,51,76" xlink:href="uri1"/>
<area map-shape="rect" map-coords="54,4,94,74" xlink:href="ur2"/>
</map>
</map-group>
This XML closely resembles its corresponding XHTML:
<img src="img-uri" usemap="#my-map-id"/>
<map id="my-map-id" name="my-map">
<area href="uri1" shape="rect" coords="1,1,51,76"/>
<area href="uri2" shape="rect" coords="54,4,94,74"/>
</map>
Secondly, the book DTD posesses a <multi-link> container element that allows combining a subject term with multiple hyperlinks providing information about that term:
<multi-link>
<term>HNF4A gene</term>
<ext-link ext-link-type="url" xlink:href="http://www.ncbi.nlm.nih.gov/gene/3172">Entrez Gene</ext-link>
<ext-link ext-link-type="url" xlink:href="http://www.ncbi.nlm.nih.gov/omim/600281">OMIM</ext-link>
</multi-link>
This is put to use in Bookshelf as follows:

Thus, the overall similarities between the book and article tagsets have facilitated use of the book DTD by Bookshelf.
Books and Journals in Practice: Bookshelf in PubMed Central
Source Conversion
Conversion of source text into the desired XML format is usually among the more complex and costly steps in the publishing cycle. This is true both for in-house conversion and third-party vendor services. Regarding the latter, it is the experience at Bookshelf that the prominence and wide-spread use of the article DTD greatly facilitates conversion of book content if the NLM format is chosen. The fact that vendors, from having worked on journal data, tend to have experience with the NLM modules, makes it comparatively easy to set up and monitor a books conversion project. This is especially the case for lower-level document objects such as citations, tables, or figures—precisely the objects for which detailed tagging instructions are usually more difficult to communicate and to enforce.
Bookshelf relies on vendor services mostly for conversion of pre-published (print) material. Source content is usually sent in PDF form for conversion to NLM XML. A benefit of integration with PMC is that tagging rules and respective documentation originally drafted for articles can be adopted for books content. Consider the following randomly chosen article tagging instructions addressing figures and collaborative document contributors:
A.
Tag all figures that must be displayed in place in the text with @position=”anchor”. Tag figures that may “float” or appear anywhere in the text without losing meaning with @position=”float”. Common characteristics of figures with @position=”float”: a) It has a label like “Fig. 1” or “Schema IV” or even just “Figure” b) It has a title or caption.b) It is referenced by an <xref> with @ref-type=”fig”
B.
Use <collab> when a group of authors is credited under a single name. Note that if an author is identified as writing on behalf of a collaboration or organization, you must use <on-behalf-of>, not <collab>.
Both of those article tagging rules can equally be applied to books. Rather than reinventing the wheel, Bookshelf attempts to draw and benefit as much as possible from the experience of article tagging at PMC.
A second area where close integration of books and articles is beneficial concerns in house conversion. A large number of publishers submit content in a variety of schemas to PMC, which is then converted to the desired article XML. Over time, PMC has developed a very large and well tested XSLT library. At Bookshelf, respective code is borrowed to also handle books content: Code usage includes generic modules, for example to convert dates into varying formats or to perform other more complex string operations, as well as object level conversion modules, for example to transform tables according to CALS/OASIS in the XHTML model employed by JATS.
Data Processing and Ingesting
After source XML in NLM format has been created, Bookshelf continues to leverage off the infrastructure built by PMC around article XML. The fact that articles and books share most of their tagging modules facilitates this in several ways, as the following examples illustrate:
- During the ingest process PMC software checks article references in the source xml as to whether a PubMed ID has been provided for a particular citation. For missing links to PubMed the software attempts to resolve the citation by looking up the respective PMID. If successful, it writes in form of <pub-id pub-id-type=”pmid”> back in to the xml. Since there is essentially no difference between a citation element in a book and a citation element an article, it was possible to put the “article software” to use for books data at practically no additional cost.
- Similarly, article validation methods that check for the existence of unparsed data like images and pdf files have could be adopted for Books data as the elements that link xml to binary objects (<graphic>, <inline-graphic>, or <media>) are the same across book and articles modules.
- An important part of most ingesting and loading processes is to extract key data from the XML and store it in database fields. Books in PMC could, again, rely on existing and proven article methods, for example for extracting document dates from the <history> element or subject matter designations from <subj-group>.
The above mentioned natural difference between books and articles in composition level necessitates however also special treatment of books data: While an article XML-document can be created, stored, and delivered as a single object, a book document, due to its size and relative structural complexity, cannot be handled in the same manner. In order to resolve this problem, each book is initially stored in a content management system separate from articles. Prior to loading the document into the PMC Books database, a single <book> XML-document is transformed into a number of independent, self contained <book-part> documents. The conversion process includes three main tasks:
- 1.
To create an actual <book-part> document out of the encompassing <book> document and place information about the parent source (<book-meta>) into every part
- 2.
To create a Table of Contents <book-part> document which contains links to all newly created parts and in this way, comes to represent the book
- 3.
To resolve crosslinks between book-parts and transform linking elements that are based on ID/IDREF mechanism (<xref>s) into alternatives with CDATA attribute types so as to allow independent validation of a part, once the book context is removed.
This process, the creation of independent “article-like” book-parts, is the practical key to handling of books and journal content within the same system (see Figure 1).

Figure
Figure 1. Conversion of <book> to <book-part>.
XML Rendering
XML serves as the source for (1) multiple output formats, such as HTML and PDF; (2) destinations for display of content, such as Bookshelf and PubMed; and (3) uses such as building RSS feeds, collection lists, catalog records, and citations.
Content is delivered as HTML to the web from XML dynamically during render time. Infrastructure originally built by PMC for the delivery of article content is also used for displaying books on to the World Wide Web. Firstly, Bookshelf does not need to maintain software to render complex text objects, such as equations tagged in MathML. Mapping of special characters, another fairly difficult issue, is also taken care of on the article side. For both books and articles, conversion of the XML to (X)HTML is primarily based on XSLT. Bookshelf can rely on PMC in this area: The book viewer starts out with importing the complete set of article XSLT modules. Book-specific needs are addressed by either completely overwriting or partially modifying the respective article templates. Where article rendering is applicable also to books, the respective code is simply applied to the XML data. Thus, a lot of time and energy can be saved. For example, the various components of the <citation> element into a proper text string would usually require a major coding effort. Due to integration with PMC and usage of the same vocabulary, however, it can be reduced to a few simple lines, such as:
<xsl:template name="render-citation-in-book">
<xsl:call-template name="render-citation-in-article">
</xsl_template>
Bookshelf also creates PDF files from XML for a subset of books. The same approach has proved valuable, where code used to build PDFs for the NIH Manuscript Submission System (NIHMS) in PMC is used for the generation of PDFs for Bookshelf.
The NLM Book DTD Accomodates Varied Publication Types in Bookshelf
Bookshelf includes prepublished books, reports, small monographs, electronic books, and large databases. The main <book> container has been made to hold from a single <book-part> document to more than eight hundred <book-part>s. Bookshelf has found a way to accommodate these varied publication types using the NLM Book DTD. Publication type information is captured in <custom-meta>:
<custom-meta>
<meta-name>books-source-type</meta-name>
<meta-value>Database</meta-value>
</custom-meta>
In the case of a very large resource with over three thousand <book-part> documents, Bookshelf has bypassed the creation of a single XML document with the root element <book>; instead moving on to the creation of independently validating <book-part> documents, which saves time. Thus, books have also gained entry into the PMC database at different entry points.
Workflows
Below, is a description of the type of workflows in Bookshelf:
Submission of PDF files or Word Documents
Content is submitted to Bookshelf as PDF files. There may be one PDF file for the whole book or multiple PDF files. In the past, the Bookshelf has also received submissions of Quark files, but that is not found to be common practice these days. PDF files are submitted to a vendor for conversion to XML in the book DTD as per specifications developed between Bookshelf and vendor. XML files are uploaded to the Bookshelf content management system, validated against the DTD, and then loaded to the PMC database.
XML Submission Using NLM Book DTD
Content is submitted to Bookshelf as XML files in the NLM Book DTD v2.3. XML files are uploaded to the Bookshelf content management system, validated against the DTD, and loaded to the PMC database.
XML Submission Using External DTDs
XML files submitted in external DTDs run through XSLT converters to transform them to the NLM Book DTD v2.3. XML files have been submitted in DocBook v4.4, NLM DTD Journal Publishing DTD v2.3, and other proprietary DTDs. The converted files are validated following conversion, uploaded to the Bookshelf content management system, and then loaded to the PMC database. As mentioned above, some books have bypassed the content management system.
XML Creation Using the NCBI Word Converter
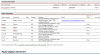
Authors use a Microsoft Word template for authoring chapters, appendices or glossaries. In this workflow, each Microsoft Word document thus corresponds to a chapter or appendix in a book. Metadata information, such as title, publication history, and contributor information is captured using tables at the top of the document (see Figure 2). The template contains a predefined style palette (see Figure 3). Styles are applied to respective parts of the document such as the title, headings, preformatted text, and table and figure captions. Using the information provided in the metadata tables, structure of the Word document, and style of text elements in the document, structure and semantic meaning is preserved upon conversion to XML.
Figure
Figure 2. Word authoring template showing tables for capture of metadata for chapters

Figure
Figure 3. Word authoring template showing style palette and styles applied to document
Using the NCBI Word converter tool (which utilizes eXtyles software for reference processing, Inera Inc.[3]), the document is converted to XML in the NLM Book DTD. The root element for the output file is <book-part>. Validation of XML is performed, ignoring external document references, and errors are reported when the job is completed.
Authors upload the document to the content management system which contains the XML document with root element <book>.This document includes the doctype declaration, book metadata and entity declarations for chapters. If a new chapter is added, the book master file is edited.
Using this workflow, Word documents can be edited whenever desired, and the instant HTML preview makes it easy to visualize the web display. Documents need to be correctly marked up with correct outline level and appropriate styles.
Standardization of Data
Bookshelf utilizes the PMC Stylechecker (4) at two points in the workflow. The purpose of the stylechecker is to check for conformance in XML submitted through the different workflows, so that rendering rules can be built based on a single source XML. First, the stylechecker is applied to the whole <book> XML document in the Bookshelf content management system. This step was provided as a time-saving option. The second stylecheck occurs on the individual <book-part> files which are created from the <book> XML. Failure to pass the stylecheck results in failed loading to the PMC database.
Integrating Text in Bookshelf with Content-specific Database Information at NCBI
Some large database-type resources on Bookshelf have closely related data in external databases at NCBI. One example is the GeneReviews resource in Bookshelf. GeneReviews is a collection of reviews on various genetic disorders, authored by experts in the field. A closely related database called GeneTests, lists information on tests and services, provided by clinics, and contains information on various genes associated with these disorders (5). Part of the information on the rendered page in Bookshelf is created directly from the GeneTests database, using information from Entrez Gene and OMIM. This information is provided on an external server in XML in the NLM Book DTD, and integrated dynamically, during render time, relying on processing instructions in the Bookshelf XML. In this way, the most current factual information pertaining to the resource can be maintained with relative ease.
In the Bookshelf XML file, the PI <?get-external-xml molgen.tables?> will pull in the section <sec id="molgen.tables" > from the external XML file shown below; also see the rendered view.
<!DOCTYPE sec SYSTEM "book.dtd">
<sec>
<title/>
<sec id="molgen.tables" >
<title/>
<p content-type="molecular_genetics"><italic>Information in the Molecular Genetics and OMIM tables
may differ from that elsewhere in the GeneReview: tables may contain
more recent information. —</italic>ED.</p>
<table-wrap id="pkd-ar.molgen.TA" position="anchor">
<caption>
<p>Table A. Polycystic Kidney Disease, Autosomal Recessive: Genes and Databases</p>
</caption>
<table>
<tbody>
<tr>
<th>Gene Symbol</th>
<th>Chromosomal Locus</th>
<th>Protein Name</th>
<th>Locus Specific</th>
<th>HGMD</th>
</tr>
…
Conclusion
Bookshelf has used features offered by the NLM Book DTD, such as the close similarity between the book and article tag sets, and flexibility offered by the book DTD in tagging various types of resources, as well as the infrastructure offered by PMC to its advantage in building a robust textual resource for the delivery of biomedical information. In addition, because Bookshelf is a part of the linked network of databases at NCBI, the most current relevant information can be displayed to the user, through cross-talk between databases, offering advantages in the maintenance of data in the rapidly advancing fields of medicine and healthcare.
Acknowledgements
We wish to credit our colleagues at the National Center for Biotechnology Information, for their contributions to the Bookshelf project; especially, members of the Bookshelf team, Sergey Krasnov and the PMC team of developers, Jeff Beck for his advice on the DTD and help with books, and Karanjit Siyan for development and support of the Word converter tool. We thank Jim Ostell, Chief, Information Engineering Branch, NCBI and David Lipman, Director, NCBI, for their vision and support of the Bookshelf project.
References
- 1.
- NLM Journal Archiving and Interchange Tag Suite. Available at: http://dtd
.nlm.nih.gov/ - 2.
- TEI: Text Encoding Initiative. Available at: http://www
.tei-c.org/index.xml. - 3.
- eXtyles, Inera Inc. http://www
.inera.com/extylesinfo.shtml. - 4.
- PMC Stylechecker. Available at: http://www
.pubmedcentral .nih.gov/utils/style_checker /stylechecker.cgi. - 5.
- Sayers EW, Barrett T, Benson DA, Bolton E, Bryant SH, Canese K, Chetvernin V, Church DM, Dicuccio M, Federhen S, Feolo M, Geer LY, Helmberg W, Kapustin Y, Landsman D, Lipman DJ, Lu Z, Madden TL, Madej T, Maglott DR, Marchler-Bauer A, Miller V, Mizrachi I, Ostell J, Panchenko A, Pruitt KD, Schuler GD, Sequeira E, Sherry ST, Shumway M, Sirotkin K, Slotta D, Souvorov A, Starchenko G, Tatusova TA, Wagner L, Wang Y, John Wilbur W, Yaschenko E, Ye J. Database resources of the National Center for Biotechnology Information. Nucleic Acids Res. 2010;38(Database issue):D5–D16. [PMC free article: PMC2808881] [PubMed: 19910364]
- Introduction
- The NLM Book DTD in Context of JATS
- Books and Journals in Practice: Bookshelf in PubMed Central
- The NLM Book DTD Accomodates Varied Publication Types in Bookshelf
- Workflows
- Standardization of Data
- Integrating Text in Bookshelf with Content-specific Database Information at NCBI
- Conclusion
- Acknowledgements
- References
- Bookshelf: Leafing through XML - Journal Article Tag Suite Conference (JATS-Con)...Bookshelf: Leafing through XML - Journal Article Tag Suite Conference (JATS-Con) Proceedings 2010
Your browsing activity is empty.
Activity recording is turned off.
See more...